
Efficient auto-scaling scheme for rapid storage service using many-core of desktop storage virtualization based on IoT
Oct. 2016. By Young-Sik Jeong
Keyword: Storage service, Desktop storage virtualization, Cloud computing, Graphic processing unit, Internet of Things
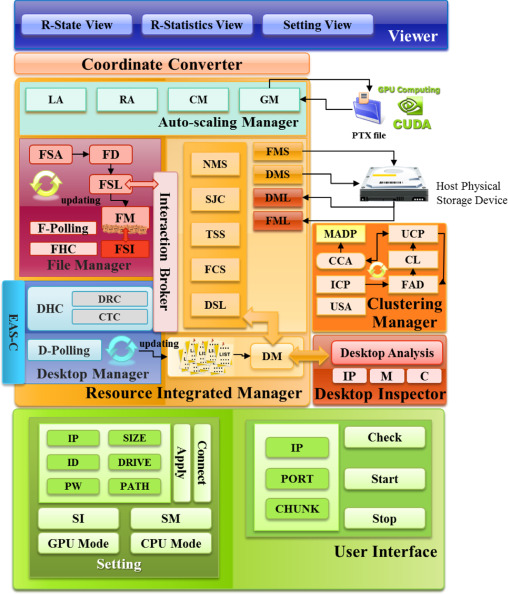
Following the progressive development of IT technology, on-premise IT resources have been shifted to cloud computing environments. The principle reason for this change in IT resource-composing environments is that cloud computing services allow IT resources to be used as and when necessary, which means without buying hardware equipment. For this reason, studies on diverse aspects are being conducted for better security, rapidity, availability, reliability, and elasticity of cloud computing. Among the virtualization technologies that are basic for cloud computing, desktop storage virtualization (DSV) is composed of distributed legacy desktop personal computers. In DSV environments, clustering by unavailable state time and auto-scaling for storage provision as requested by users are considered very important. In addition, deferred processing for analysis of desktop PC performance states in DSV environments to select an appropriate desktop PC is directly connected to the quality of service (QoS). Although diverse algorithms and schemes for clustering and auto-scaling have been developed to this end, they have limited performance or have been made without considering DSV environments. Consequently, large amounts of deferred processing time are required.
In this research, an efficient auto-scaling scheme (EAS) is proposed that minimizes deferred processing time in Internet of Things (IoT) environments by using many-cores of the GPU for clustering and auto-scaling in DSV environments. The EAS provides higher QoS to storage users compared to the CPU by mapping the information of numerous distributed desktop PCs on individual threads of the GPU and processing the information in parallel.